This is not the canonical version of this post.
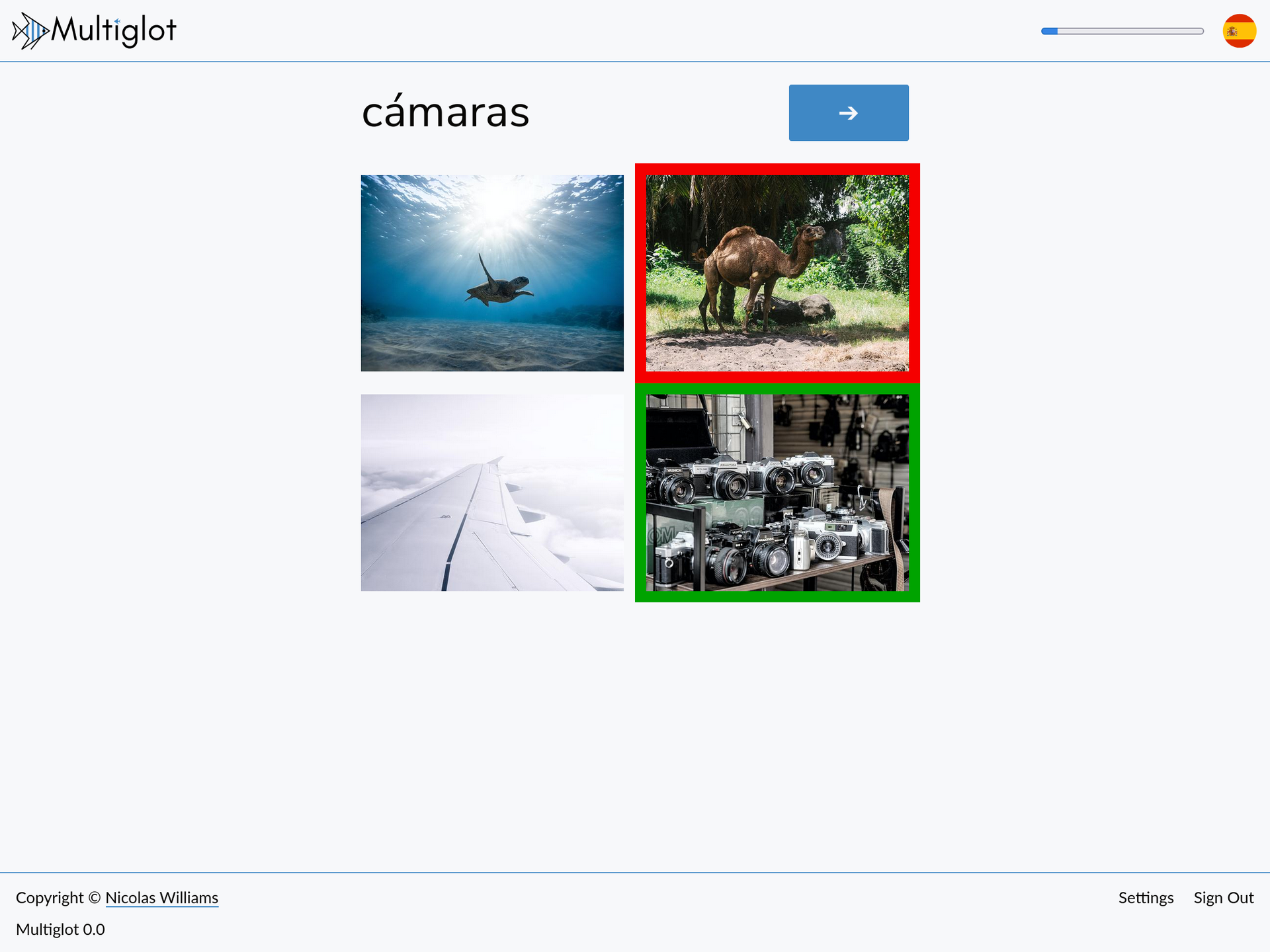
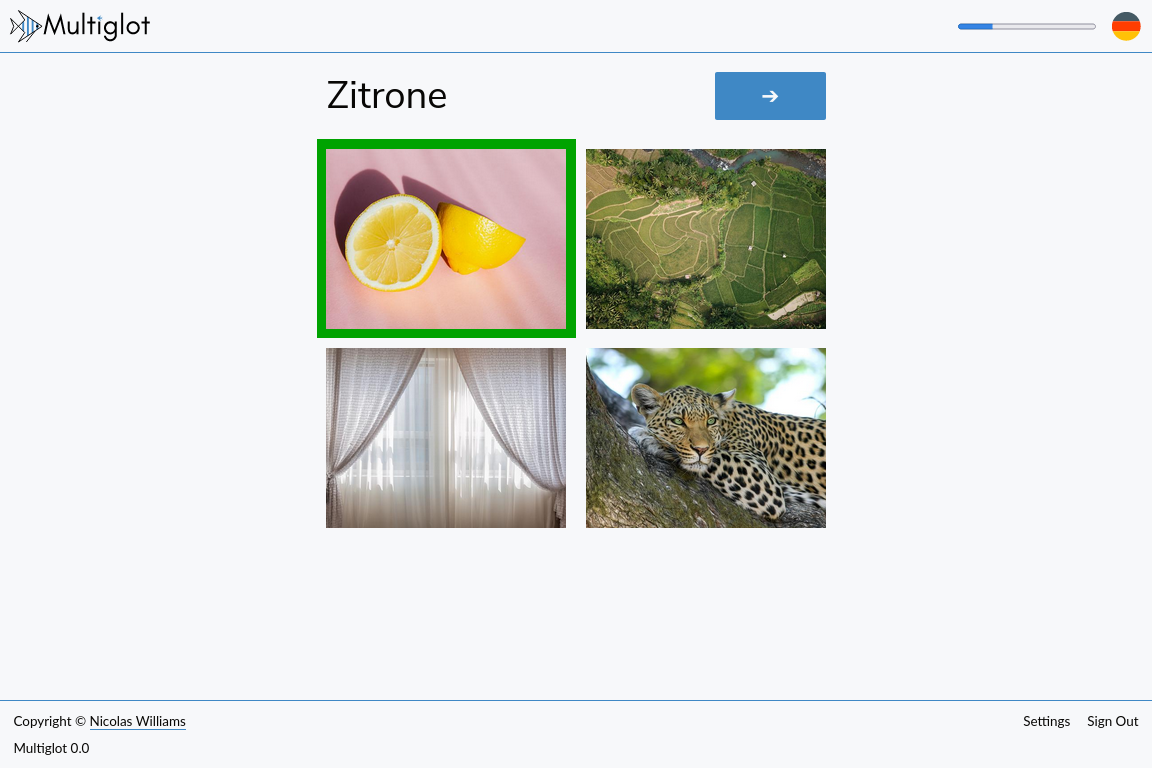
Multiglot 9 is here! And with it, a new type of activity: choose the word from the list which best describes the image. The list of words will be made from the words you’re already learning, giving you a chance to sort out any confusion between them. This activity will appear automatically once you’re ready, and is a stepping stone to being asked to spell the word correctly. To power this, we’ve created over 3000 extra flashcards for you!